
Give me six hours to chop down a tree and I will spend the first four sharpening the axe — Abraham Lincoln
We will begin with some prerequisites topics. In the previous blog, I used some terms - sk_buff, NAPI, SoftIRQ, XDP, and TAPs; in this blog, I am going to cover these in as much detail as required for us to understand their role in the packet receipt path.
The questions I would tackle in the prerequisites are :
- How does the CPU know which function to call when the NIC interrupts it? Is it hardcoded?
- What did I mean by DMA and ring buffers?
- What is NAPI, and what is its role in the Linux Kernel?
- How is a packet represented in the Linux Kernel and headers accessed?
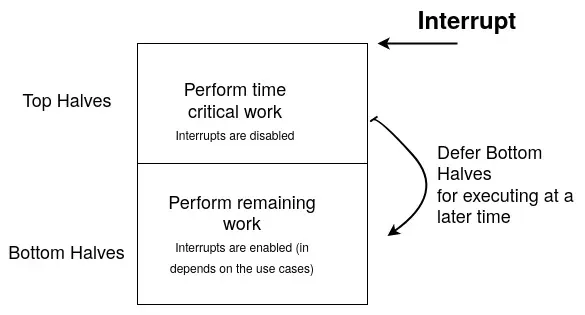
Interrupts
How does the CPU know an event, such as an I/O from the disk or a keyboard button press, has happened? Since the Linux Kernel is preemptive, the hardware devices “interrupt” the CPU from its execution. The CPU then performs the required action, such as getting the keyboard press’s keycode or the data available from the disk controller. Now, this can take a lot of time (in terms of CPU time) and exhaust other programs’ CPU timeslice. To alleviate this, the Linux Kernel uses a 2-step process:
- The top and bottom half. The top half runs the hardware IRQ or hardirq, which performs time-critical functions, like acknowledging and storing the key code. These hardirqs can generate Software IRQs or softirqs, generally used to defer work to the bottom half.
- The bottom half is responsible for most of the processing, such as sending the
keycode to the terminal or passing the I/O data to the user space program. There
are many approaches to run these types of work, including using kernel
threads. The networking subsystem uses this approach. ksoftirqd are
per-thread processes that are assigned the bottom half handlers. The bottom half
handlers are registered by the driver or by the kernel subsystem using
kernel API functions. For example PCI driver use
irq_requestorpci_alloc_irq_vectorsfor this purpose.
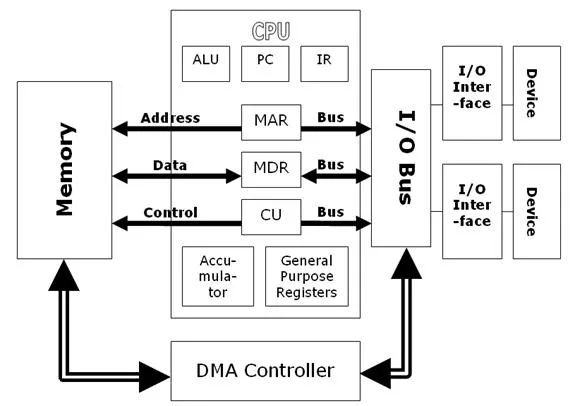
DMA and Ring buffers
Due to the attention span of the reader I would not go into details, instead I encourage the user to look these up on the web and grasp a basic understanding.
- The kernel has access to the RAM or the memory. This physical memory is divided into Pages to enable faster address lookups.
- The kernel assigns virtual addresses to all the processes to isolate them. The processes then safely assume that it is the only process running on the system, apart from the kernel. The programs instruct the CPU to load data from memory into registers (see LDR and STR instructions). So, the CPU is responsible for translating this virtual memory to the physical page number and, hence, the physical address.
- Hardware like Memory Management Unit (MMU) and Translation Aside Buffer (TLB) are used together to handle this. The TLB acts as a cache for fast lookup, and MMU raises a Page Fault interrupt, which the kernel then serves. This entire flow is similar for I/O devices, where IOMMU performs the same function effectively.
- So, if an I/O device needs to access the memory, it must request it to the CPU. I/O devices like NIC, which receive a lot of packets and copy them to the memory at a very high rate, this step can be a bottleneck. Hence, a DMA (Direct Memory Access) controller is used that bypasses the CPU and interacts directly with the memory.
Let’s move on to Ring buffers. Ring buffers are circular buffers that have two pointers pointing to the data. One is controlled by the producer, and the other by the consumer. The producer adds data and advances the pointer, whereas the consumer consumes the data and advances the pointer. Wikipedia has a great article on circular buffers.
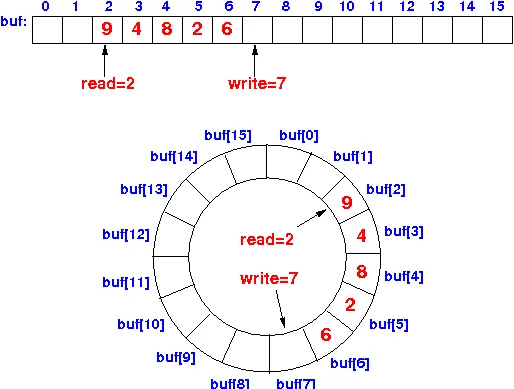
This data structure is used in many drivers. The benefits of using Ring buffer for networking are :
- Ring buffer reuses the memory instead of allocating new ones. So, once a block of memory is consumed, it is instantly available to the producer.
- When the system is overwhelmed with packets, the buffers get overwritten by the producer side, which avoids memory thrashing. Thrashing happens when the kernel needs more memory, the CPU is busy flushing pages to the disk, and no meaningful work is done.
So, what does a DMA + Ring Buffer mean? This means that the NIC sends the packets to a Ring Buffer in the RAM directly using DMA. As you can see in the image below, the NIC is the producer and the NIC driver is the consumer. We will come to this in the next blog.
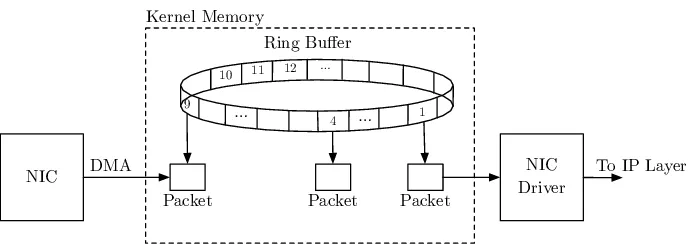
NAPI
In the previous section, I mentioned that the NIC interrupts the CPU after putting the arrived packet in the DMA Ring buffer. This is called an event-driven approach and is used widely by the Linux Kernel. However, this approach has an issue for high-speed networking, which is noticeable once interruptions increase.
Every time an interrupt is issued, the CPU must serve it to acknowledge it. When the system is under a heavy load of processing the packets, a high frequency of interrupts causes the CPU to waste CPU time in serving the interrupt rather than performing useful work. These interrupts do not provide much valuable information except that a packet has arrived, which the CPU already knows about.
The most popular interrupt mitigation technique is to perform polling. This was introduced to the Linux Kernel through a series of patches known as the New API or NAPI 1 2 (now NAPI doesn’t stand for anything).
-
In this approach, the CPU acknowledges the interrupt -> schedules the handler -> disables the interrupt during times of high traffic.
-
The interrupt handler runs and processes multiple packets in batches. However, there is a caveat: if there are a lot of packets in the batch, the processing would also affect the performance under heavy load. So, NAPI provides a parameter called budget to the NAPI-compliant drivers. The drivers can only process the budget amount of packets and no more. This budget is tunable based on the requirements. If the budget is high, it will starve other processes on the system, and if the budget is too low, it will have the same effect as interrupts.
-
If the system is under heavy load, it is better to drop the packets sometimes. NAPI allows the drivers to drop packets at the hardware level, which is much better than dropping the packet after partial processing by the CPU.
I will discuss NAPI functions and interaction with the NIC driver and the Kernel in my next blog.
Socket buffers
Every packet has data encapsulated by network and transport headers. The Kernel also maintains metadata for each packet for accessing, updating, accounting, filtering, and other purposes.
The metadata is stored in a data structure called sk_buff, and skb is commonly used to refer to an instance of sk_buff throughout the Kernel. As I already mentioned in my previous blog, the Kernel implements four layers, and each perform different operations on packet, this would require copying the packet through all layers. Instead, the Kernel intelligently manages pointers to the different sections of the packet.
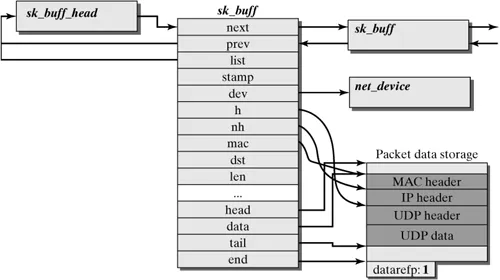
As shown in figure 4.1, the data structure also holds information about the network device (dev), mac, and routing information (dst). Hence, sk_buff is a critical data structure, and the Kernel passes pointers to this through all the layers instead of copying the packet. The figure below illustrates the moving of pointers when kernel adds headers or data to the packet.
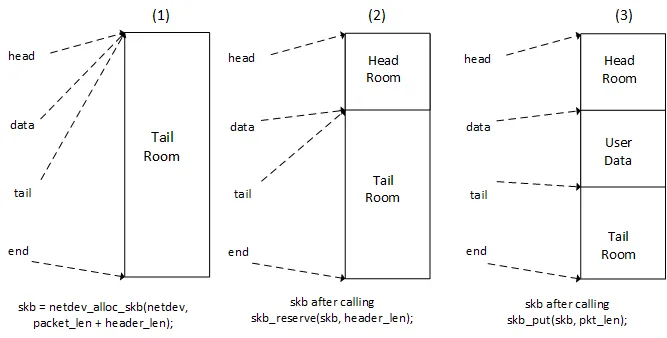
You can read about sk_buff in detail at Kernel Docs, Linux Foundation wiki on sk_buff and at a great blog by A.M.Sekhar Reddy. I encourage the readers to visit the introduction paragraph and ponder upon the four questions I raised based on your understanding of this blog. Thank you for reading !