Implementing a low-level container runtime
Prerequisites
- To get started we need to be through the basics of Linux Kernel Namespaces and Linux cgroups.
- Follow the blog series by Hechao Li : Mini Container Series Part 0
- Reference Code : container-runtime
Phases in starting a container
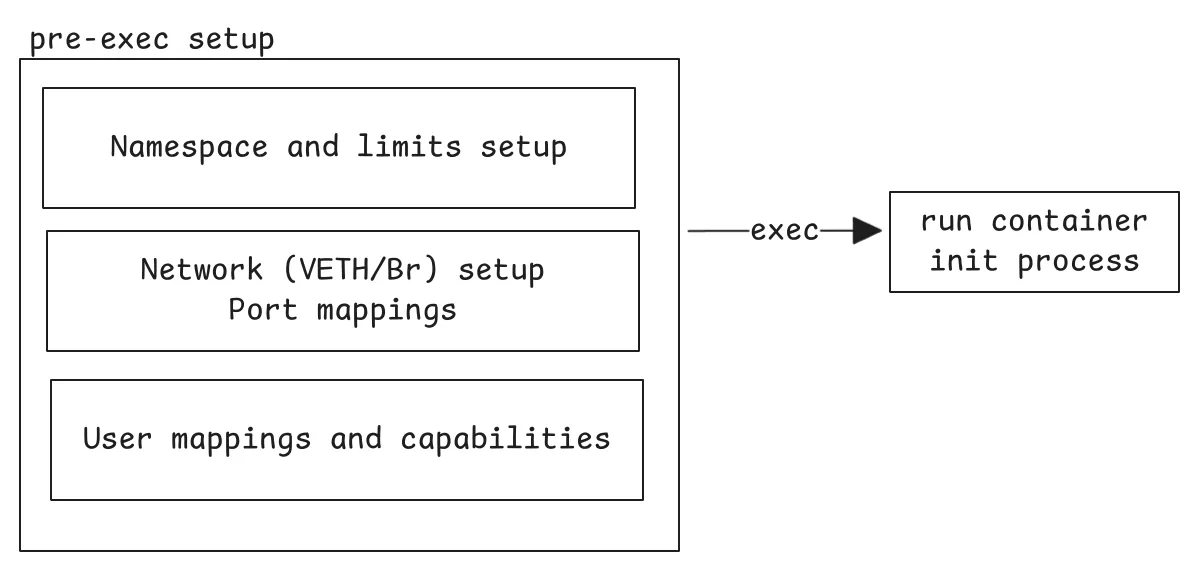
User NS, Privileges and UID/GID mappings
If we use clone using the flags CLONE_NEWUSER, it creates a new user namespace. the execed process spawns with UID 0 in then
new namespace, but what is it’s UID in the parent namespace? If the child process creates a file in the shared filesystem, what will
be the UID and GID of the file ? This is done by using UID mappings and GID mappings.
- The file
/proc/PID/uid_map(PID of child in parent ns) determines the mapping of UID of the child process ftom thehostto thecontainer. - Similary the file
/proc/PID/gid_mapdetermines the mapping of GID of the child process. - By default, the file is empty with no entries, in those cases UID mentioned in
/proc/sys/kernel/overflowuidand GID mentioned in/proc/sys/kernel/overflowgidis used in the host for the child process (the child has UID 0 in it’s own namespace). So if the child creates a file in the shared namespace, it will have UID and GID as65534(value of overflowuid in my kernel) in the parent namespace.
For more information on UID and GID mappings, and the format of mappings, see user_namespaces(7). We can perform the mapping after the clone, using the following code :
static int update_map(char *path, char *buf, size_t size) {
int fd = open(path, O_WRONLY | O_CLOEXEC);
if (fd == -1) {
pr_err("error in opening file (%s): %s\n", path, strerror(errno));
return -1;
}
if (write(fd, buf, size) < 0) {
pr_err("error in writing to file (%s): %s\n", path, strerror(errno));
close(fd);
return -1;
}
close(fd);
return 0;
}
int setup_uid_gid_map(int child_pid)
{
// open the uid_map file and write the string
// we will use hardcoded value from /proc/$$/uid_map
// this will map users starting from 0 to (0 + 4294967295) from the host
// and 0 to (0 + 4294967295) in the container.
// So 0 in host is 0 in container (hence privileged)
char uid_map_path[256];
char gid_map_path[256];
char *map_buf = "0 0 4294967295";
snprintf(uid_map_path, 255, "/proc/%d/uid_map", child_pid);
snprintf(gid_map_path, 255, "/proc/%d/gid_map", child_pid);
if (update_map(uid_map_path, map_buf, strlen(map_buf)) < 0) return -1;
if (update_map(gid_map_path, map_buf, strlen(map_buf)) < 0) return -1;
return 0;
}References
Network setup
Setting up the file-system
There are multiple steps involved in setting the file-system of a container. It is suggested to use pivot_root as a stronger mechanism to prevent chroot jail escape.
The conditions for a successfult pivot_root are :
- The
old_rootand thenew_rootshould be a mount point (can be enforced usingMS_BINDto self). - For child namespaces, the rootfs (
/) should be mount asMS_PRIVATEorMS_SLAVEto prevent changes the child namespace propagate to the parent namespace
The steps involved in pivot_root are :
- Mount
/asMS_PRIVATE | MS_REC. - Bind mount the new rootfs using
MS_BIND - Open
/and thenew_rootas passed by the user and get their file-descriptors. - Change the directory to the new root fd using
fchdir. - Then we perform the pivot_root using a special case (which allows us to do this without creating a directory in the new_root).
- Mount the
procfsbefore we unmount the oldroot, otherwise we getEPERMerror on mounting procfs. - Then we go back to the old root (
fchdir), and then unmount the old root. Here is the code without error-handling. You can also mount the proc file-system if you need.
// mount the current fs as MS_PRIVATE to prevent child mounts from propagating
mount(NULL, "/", NULL, MS_REC | MS_PRIVATE, NULL);
// ensure the new root mount point is a mount point, by doing a MS_BIND mount
mount(ctx->rootfs, ctx->rootfs, NULL, MS_BIND, NULL);
// get handles for oldroot and newroot
int oldroot = open("/", O_DIRECTORY | O_RDONLY, 0);
int newroot = open(ctx->rootfs, O_DIRECTORY | O_RDONLY, 0);
// change directory to the new root to perform pivot
fchdir(newroot);
// perform pivot root
syscall(SYS_pivot_root, ".", ".");
// mount the procfs before we unmount the oldroot
mount("proc", "/proc", "proc", MS_NOSUID|MS_NOEXEC|MS_NODEV, NULL);
// go back to oldroot. Why ?? : we need to unmount the oldroot
fchdir(oldroot);
// unmount the old one
umount2(".", MNT_DETACH);
// go to the new root
chdir("/");Namespace and cgroup setup
Namespaces
- To setup the namespace, you can either use
unsharein the child process, orclonein the parent process. I avoidedunshareto avoid closing the inherited file descriptors and other cleanups. I expectedcloneto be clean. - For clone you can just call it using the flags. I used the raw syscall, since the
glibcwrapper requires a starting function for the child.
int flags = CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWUTS | CLONE_NEWIPC
| CLONE_NEWNET;
pid = syscall(SYS_clone, SIGCHLD | ctx->flags, 0, NULL, NULL, 0);
if (pid == -1) {
/* error */
} else if (pid == 0) {
/* child */
setup_rootfs();
exec();
} else {
/* parent */
}Cgroup
There are two ways to add a new process to a cgroup:
echothe PID of the child process tocgroup.procsfile.
- This has a few drawbacks, such as the child PID should be known beforehand, so this must be called after the child process is created.
- To do this before execing the program in the child process, there must be synchronisation mechanism between the parent and the child process. The parent process moves the child to the cgroup and then signals the child process.
- Synchronisation with child is difficult in cases when the child is cloned with flags like
CLONE_NEWNS,CLONE_NEWIPCand withoutCLONE_VM, the memory region of the child is not shared with the parent. So synchronisation methods likemessage queues,semaphores,shared memorydo not work well (as far as I exprerimented, I could be wrong about this!).
- using the
CLONE_INTO_CGROUPtoclone3syscall.
- This method does not require any synchronisation methods or creating the child process beforehand. The kernel creates the child process directly into the cgroup. However, this method requries the support of
clone3and theCLONE_INTO_CGROUPflag in the kernel. - The
clone3calls takes instruct clone_argsstructure as one of the parameter. The cgroup folder must be created and after setting the appropriate limits, a file descriptor to the cgroup folder is set in thecrgroupfield ofclone_args.
struct clone_args args = {0};
args.flags = ctx->flags; // flags such as CLONE_NEWNS, etc.
args.cgroup = ctx->cgroup_fd;
args.exit_signal = SIGCHLD;
int pid = syscall(SYS_clone3, &args, sizeof(struct clone_args));Extras
There are many more features that can be implemented in a container runtime such as —
- Console or TTY setup
- Setting capabilities for the container processes
- SELinux policies
- AppArmor profiles
- Checkpoint and Restore
- Core scheduling domain (https://lwn.net/Articles/876707/)
- I/O Priority
For implementation and reference of these features, you can refer to LXC or runC implementations.
Also, I wrote an interesting blog on synchronisation mechanism between parent and child process during namespace isolation. You can read it, if you are interested.